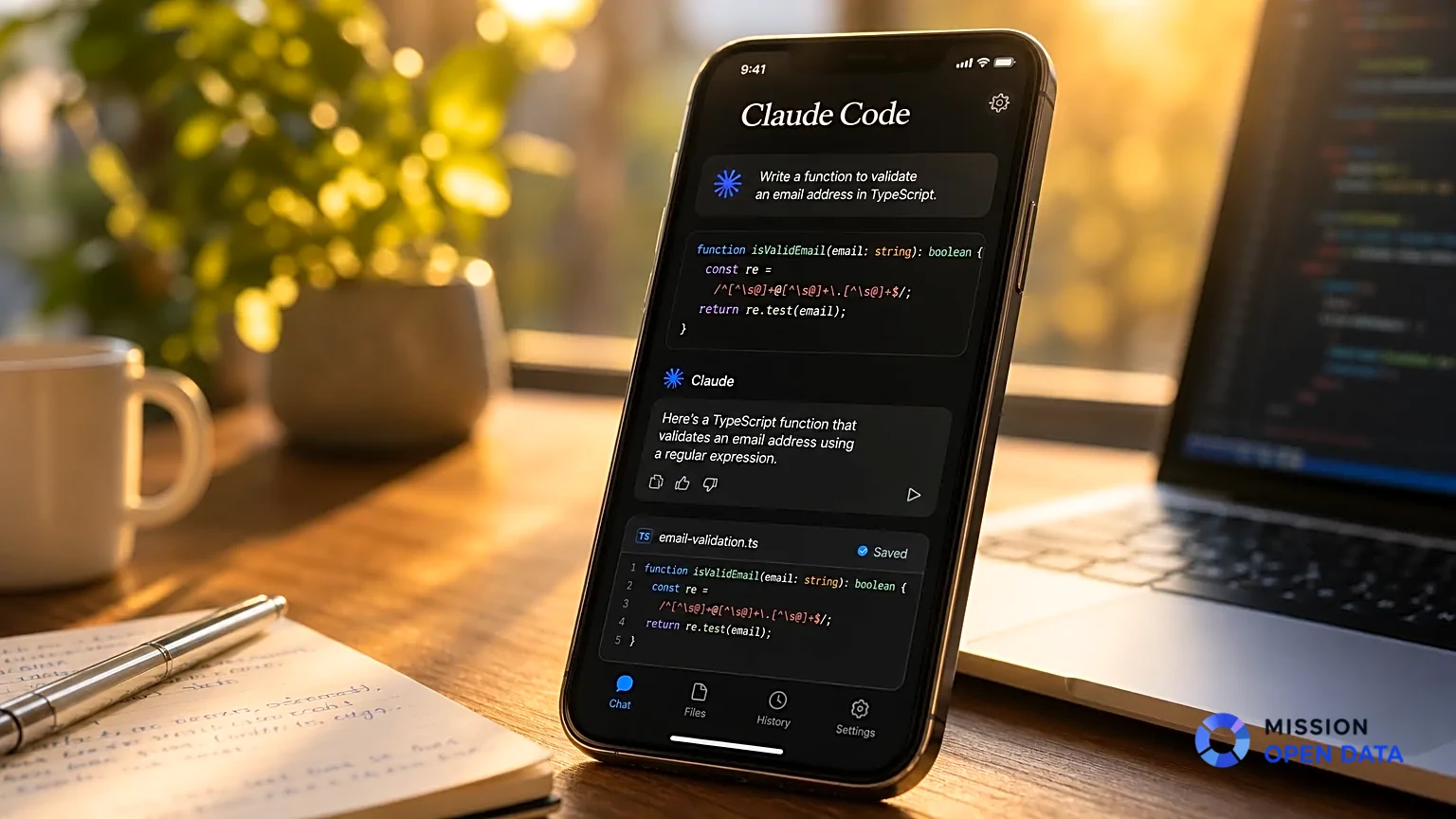
Code Review : Anthropic Claude arrive dans un moment un peu tendu pour les équipes dev. Le 9 mars 2026, Anthropic a lancé cette new feature dans Claude Code, avec une promesse simple sur le papier : relire plus de code, plus vite, sur les pull requests, sans noyer les équipes sous du bruit. Dans the docs and the blog, the company explique que code review passe par plusieurs agents, que le service tourne en research preview for Teams and Enterprise, et que you can l’utiliser sur GitHub pour examiner your PRs. Le point qui fait parler, c’est double : une revendication interne proche de 99 % de pertinence, et un coût moyen annoncé autour de 25 dollars par revue. Dit autrement, this tool vise les équipes qui produisent beaucoup, and qui veulent garder un contrôle humain sur the code before production.
Sommaire
Qu’est-ce que Code Review dans Claude Code pour la code review ?
Dans Claude Code, la fonction code review ne remplace pas le reviewer humain. Elle prépare le terrain. Quand une pull request opens, le service lit le diff, va chercher du context dans le dépôt, inspecte des fichiers en dehors du diff si besoin, puis post des comments directement sur les lines concernées.
Le focus n’est pas le style. C’est important. Le produit cherche surtout les bugs, les régressions, certains points de security et des erreurs logiques que les linters laissent passer. C’est pour ça qu’Anthropic parle d’un reviewer “for the hard stuff”, pas d’un simple outil de formatting.
Il faut aussi distinguer deux choses. Claude Code peut générer du code, et Code Review : Anthropic Claude peut ensuite relire ce même code ou celui d’un humain. Ce sont deux usages différents, même si, dans les faits, ils finissent souvent dans la même chaîne de travail.
Comment le multi-agent analyse une pull request avec 5 agents
Le mode multi-agent est la partie la plus intéressante. Au lieu d’un seul modèle qui lit tout du début à la fin, la plateforme dispatch five agents en parallel. D’après les éléments publics, on retrouve en gros ce découpage :
- un agent de détection de bug logique sur le diff
- un agent de vérification de conformité avec
CLAUDE.mdouREVIEW.md - un agent qui relit l’historique git et les zones proches du codebase
- un agent qui compare avec les anciens review comments sur la PR
- un agent final qui vérifie, déduplique et classe les findings
Le truc, c’est que chaque agent ne travaille pas isolé dans un coin. Il y a une phase de vérification croisée. C’est là que la promesse “moins de 1 % de retours jugés incorrects” prend du sens. Anthropic parle d’une échelle de confiance de 0 à 100, avec un seuil par défaut autour de 80. Les signalements faibles restent en retrait. Les plus solides remontent.
Franchement, c’est plus malin qu’un bot qui commente tout ce qu’il voit.
Tests pratiques : code review sur une PR JavaScript et une PR Python
Sur une PR JavaScript de 220 lines qui touche un handler Express, you can lancer un examen local avec la commande suivante si le plugin est installé :
/code-review
Ou, côté PR GitHub en mode manuel :
@claude review
Exemple de diff JS :
app.post("/login", async (req, res) => {
const user = await db.findUser(req.body.email);
if (user.password === req.body.password) {
res.json({ token: createToken(user.id) });
}
});
Ici, le review peut find un souci évident : comparaison de mot de passe en clair, absence de gestion d’erreur, et réponse possible sans return. Sur un repo réel, ce genre de findings are souvent remontés avec une explication et un fix proposé.
Pour Python, prenons une PR de 84 lignes sur FastAPI :
@app.get("/items/{item_id}")
def get_item(item_id: int):
item = cache.get(item_id)
if item:
return item
data = db.fetch(item_id)
cache.clear()
return data
Là, la machine peut signaler un effet de bord sur le cache, voire un risque de régression si plusieurs requêtes arrivent en même time. Ce n’est pas magique, but c’est utile. Et sur du code généré en mode vibe ou coding rapide, ce premier filtre aide vraiment.
- commande locale
/code-reviewpour start une revue ciblée - commentaire
@claude reviewdans une pull request - lecture du diff plus lecture du dépôt en full context
- publication de comments inline sur github
- synthèse finale avec score de confiance et gravité
Code review Anthropic : architecture multi-agent
Description des agents spécialisés dans l’architecture multi-agent
L’architecture multi-agent de Code Review : Anthropic Claude repose sur des rôles séparés. Ce n’est pas juste du marketing, même si le mot tourne déjà sur LinkedIn et dans pas mal d’articles tech. Le gain vient surtout du fait que plusieurs lectures du même patch arrivent par des chemins different.
- agent de logique métier, il cherche les errors discrètes
- agent de règles projet, il lit
CLAUDE.mdet parfoisREVIEW.md - agent d’historique, il regarde les changements proches ou anciens
- agent de security, plus léger que code security mais utile
- agent d’agrégation, il garde le signal fort et jette le reste
A ce propos, multiple lectures valent mieux qu’un seul passage rapide. Sur une grosse PR de plus de 1000 lignes, l’étude interne dit que 84 % des PRs remontent des issues, avec 7,5 problèmes en average. Pour les petites, moins de 50 lignes, le niveau baisse autour de 31 %. Ce contraste est logique.
Filtrage des findings par score de confiance et métriques à 99 %
Le filtre par score évite beaucoup de bruit. Chaque observation reçoit une note de confiance. Si vous laissez le seuil à 80, seuls les éléments jugés high confidence arrivent dans les review comments. Résultat : moins de false positives visibles, donc moins d’agacement côté équipe.
Les chiffres internes publiés par Anthropic sont ceux qui reviennent partout :
- 16 % des PRs recevaient des commentaires utiles avant usage interne
- 54 % en reçoivent now
- moins de 1 % des retours sont marqués incorrect
- la durée moyenne d’une revue tourne autour de 20 minutes
- la production de code par engineer aurait augmenté de 200 % sur un an
Attention quand même. Ce 99 % n’est pas une garantie absolue. C’est une mesure interne, sur leur environnement, dans un cadre donné. Pour un passage en production, il faut refaire vos propres tests, sinon vous pilotez à l’aveugle.
Intégration technique avec API, plugin et github action
Côté intégration, vous avez deux voies. La première passe par le service géré dans le web de Claude Code. La seconde passe par un github action ou un plugin plus léger. Les deux existent, mais ils ne jouent pas dans la même catégorie.
Exemple d’appel API simplifié :
curl https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-d '{"model":"claude-opus","messages":[{"role":"user","content":"review this diff"}]}'
Exemple d’action CI :
name: Claude review
on:
pull_request:
jobs:
review:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: anthropics/claude-code-security-review@main
with:
claude-api-key: ${{ secrets.CLAUDE_API_KEY }}
comment-pr: true
Le github action open source est plus simple, plus contrôlable, souvent moins cher, mais il va moins loin que la version managée. C’est justement là que la comparaison “premium service” prend tout son sens.
| Mode | Usage | Coût indicatif |
|---|---|---|
| Service géré Claude Code | PRs complexes, full analyse | 15 à 25 dollars per revue |
| Plugin local | contrôle manuel, test avant push | variable selon token |
| GitHub Action open source | CI ciblée, audit léger ou sécurité | moins cher, mais moins profond |

Installer et configurer Claude Code Review pour vos PR
Prérequis et plans Teams ou Enterprise pour activer Claude Code
L’accès n’est pas universel. Pour l’instant, Code Review : Anthropic Claude est available en research preview pour Teams et Enterprise. Pas pour tous les comptes. Et détail qui compte, le service n’est pas dispo dans certaines config de conservation zéro selon les docs publiques.
Vous avez besoin de plusieurs briques avant de commencer :
- un compte admin Claude Code côté organisation
- les droits d’installation de l’app GitHub sur le repository
- une organisation GitHub avec PRs actives
- une clé api si vous passez par des workflows annexes
- un budget d’usage parce que les coûts montent vite
Le chiffre 148806 installations cité sur la marketplace a aidé le produit à gagner en visibilité. Mais ça ne veut pas dire que toutes ces installations tournent en mode profond sur des repos critiques. Il faut garder la tête froide.
Configuration pas à pas pour GitHub Actions et plugin Claude Code
La mise en place standard est assez directe. Vous ouvrez l’admin de Claude Code, vous liez GitHub, puis vous choisissez les dépôts. Ensuite, vous décidez si les reviews partent à l’ouverture d’une PR, après every push, ou seulement à la demande.
Voici un exemple review.yml réaliste :
name: code-review
on:
pull_request:
types: [opened, synchronize, reopened]
permissions:
contents: read
pull-requests: write
jobs:
claude-review:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 2
- name: Run review
run: echo "@claude review"
Et si vous voulez guider le moteur, ajoutez un fichier REVIEW.md à la racine :
## Always check
- New API routes must have tests
- Error messages should not leak internals
- Database migrations must be backward compatible
Le bon réflexe, c’est de start sur 1 ou 2 dépôts, pas 40. Sinon la facture part vite.
Paramètres de confidentialité, stockage et données de pull request
Question fréquente : est-ce que Claude Code envoie le code chez Anthropic ? Réponse factuelle : dans la version managée, les PRs sont analysées sur l’infrastructure Anthropic. Donc oui, une partie des données de pull request transite par leur service. Il faut le dire clairement.
Le point à vérifier chez vous :
- quels dépôts sont autorisés
- quelle policy interne couvre ce transfert
- combien de temps les logs ou artefacts sont gardés
- si des secrets peuvent apparaître dans les diffs
- si votre équipe a besoin d’une revue locale instead of cloud
Dans les faits, pour minimiser le risque, il faut exclure les fichiers générés, les secrets, et les PRs externes non fiables. Le repo open source de security review dit d’ailleurs noir sur blanc que l’outil n’est pas durci contre toute attaque de prompt injection. Ce genre de note mérite d’être read, pas survolée.
Évaluer la qualité des revues : métriques et retours
Taux de détection, faux positifs et KPI de code review
Si vous voulez savoir si l’outil tient la route, il faut mesurer autre chose que “ça a l’air bien”. Une équipe sérieuse suit quelques KPI simples. Par exemple, sur 100 PRs reviewed, combien reçoivent un signal utile, combien de findings sont confirmés par un humain, et combien sont des false positives.
- taux de PRs avec review comments jugés utiles
- taux de findings confirmés après tri humain
- délai moyen entre ouverture et correction
- nombre de bugs en production après merge
- coût moyen per PR ou par dépôt
Chez Anthropic, le passage de 16 % à 54 % de PRs avec commentaires de fond est le chiffre qui parle le plus. Ce n’est pas un détail. Ça veut dire que la revue automatisée remplit des trous que les humains laissaient passer, souvent faute de temps.
Impact sur la productivité des engineers et sur le work quotidien
L’autre donnée très commentée vient de l’étude interne : environ 200 % d’augmentation, soit quasiment 3x de code produit par ingénieur. Dit autrement, plus de coding, plus de PRs, plus de besoin de tri. Sans système de review, le goulot bouge juste d’un cran.
Je vais être direct : si vos engineers poussent 8 ou 10 PRs par semaine et que votre team relit encore tout à la main, l’outil peut faire gagner un paquet d’heures. Si vous êtes 4 devs avec 6 petites PRs par semaine, le ROI est moins évident. C’est là que beaucoup de discours marketing oublient le contexte.
Une équipe de 25 personnes qui économise seulement 15 minutes sur 120 PRs mensuelles récupère déjà 30 heures de revue. Et si un bug évité épargne une demi-journée d’incident, le calcul change très vite.
Limites connues, cas d’échec et tests avant production
La ou ça coince, c’est dans les cas ambigus. Un test manquant, une logique métier implicite, une dépendance historique bizarre, un script shell maison, un patch sur du legacy que personne ne comprend vraiment. Là, même un bon système peut se tromper ou rester silencieux.
Exemples concrets de limites :
- absence de test métier alors que le code compile
- PR minuscule mais effet de bord énorme ailleurs
- commentaire pertinent mais impossible à appliquer tel quel
- bruit sur du code généré ou déplacé sans changement réel
- lecture incomplète si votre dépôt a des règles non écrites
Bref, ne laissez jamais la machine approuver seule. They peuvent aider, they ne décident pas.
Sécurité et conformité : audits, vulnérabilités et confidentialité
Scans SAST, CVE et security sur une pull request
Le focus principal du produit reste logique et régression, pas l’audit SAST profond. Mais il y a bien une couche security. Sur une pull request, le service peut check des patterns de secret hardcodé, d’auth faible, de validation manquante ou de dépendance fragile.
Exemple courant sur Node :
const token = process.env.JWT_SECRET || "dev-secret";
Sur ce type de ligne, la revue peut lever un drapeau. Même chose pour un eval, un pickle.loads en Python, ou un endpoint sans contrôle d’accès. Pour aller plus loin, code security et le dépôt claude-code-security-review restent plus adaptés.
Politique de conservation des PR, privacy policy et réduction du risque
Sur ce terrain, il faut rester factuel. Pas de promesse juridique improvisée. Les docs publiques disent ce qu’elles disent, pas plus. Si vous manipulez du code sensible, posez noir sur blanc votre privacy policy interne, votre niveau de privacy attendu, et les dépôts autorisés.
- limitez l’outil aux repos à faible exposition au départ
- exigez l’approbation humaine sur les PRs externes
- retirez les secrets des diffs avant analyse
- gardez un journal des décisions quand un finding est ignoré
- faites un audit après 30 jours de usage
C’est moins glamour que la démo vidéo, mais c’est ce qui évite les mauvaises surprises.
Exemples concrets de vulnérabilités détectées par Claude Code
Dans les cas publics commentés, on retrouve surtout des problèmes de logique applicative plus que des CVE spectaculaires. Par exemple, un cache vidé au mauvais moment, une vérification de type cassée, ou une erreur de condition qui expose des données. Ce genre de bug passe souvent entre les mailles.
Et oui, sur LinkedIn ou dans d’other posts, ça paraît parfois exagéré. Mais une faille discrète sur une route API vaut souvent plus qu’un linter bavard.
Tarifs, cas d’usage et retour sur investissement
Modèles de prix, token usage et calcul du coût par review
Le modèle est lié au token et à la profondeur d’analysis. En public, Anthropic évoque un average de 15 à 25 dollars par revue. Beaucoup retiennent juste “25$ par PR”, mais le vrai sujet, c’est la complexity du dépôt, la taille du diff, et le mode choisi : automatique ou manuel.
- revue simple sur petit dépôt, coût plutôt bas
- grosse PR avec historique et vérifications, coût plus haut
- mode après chaque push, la facture grimpe vite
- mode manuel, meilleur contrôle du cost
- dashboards d’analytics pour voir le spend par repo
Soyons honnêtes, pour une PME, ça peut piquer. Pour une grosse entreprise qui perd 2 heures sur une régression production, ça peut paraître presque raisonnable.
Pour quelles équipes adopter Claude Code selon le volume de PR
Le meilleur fit, à mon avis, ce sont les équipes qui ont déjà adopté Claude Code à fond, avec beaucoup de pull requests et une dette de relecture visible. Typiquement :
- équipe de 20 à 200 devs avec beaucoup de PRs
- secteurs régulés ou à fort enjeu security
- produits SaaS avec déploiement fréquent
- équipes plateforme ou backend avec logique métier dense
- orgs déjà en Teams ou Enterprise
Pour l’open source, c’est plus compliqué. Le service managé vise les clients pros. L’option open source via github action ou intégration GitLab CI/CD reste parfois plus réaliste. Et pour une petite équipe, d’other tools peuvent suffire.
Calcul du ROI : heures gagnées, bugs évités et décision de passage en production
Un mini calcul simple. Si votre équipe ouvre 300 PRs par mois, et que chaque revue coûte 25 dollars, vous êtes à 7500 dollars mensuels. Ça paraît lourd. Mais si ces 300 PRs évitent ne serait-ce que 12 incidents coûteux, ou économisent 120 heures de revue senior, le bilan change.
Le bon cadre de décision :
- mesurer le coût humain d’une revue manuelle de 20 à 40 minutes
- chiffrer le prix d’un bug critique après merge
- comparer avec le cost mensuel du service
- tester sur 30 jours puis voir le delta réel
- garder un humain pour la décision finale
Ce n’est pas un achat “parce que c’est nouveau”. C’est un achat si le flux de PRs vous déborde déjà.
Questions fréquentes sur Code Review Claude
C’est quoi un code review ?
Une code review est la lecture d’un changement de code avant fusion. Le but est simple : repérer des bugs, des erreurs de logique, ou des soucis de sécurité avant que ça parte en production. Avec Claude Code, cette première passe peut être automatisée, mais la validation finale reste humaine.
Claude Code envoie-t-il du code à Anthropic ?
Dans le mode managé, oui, la pull request et son contexte sont analysés sur l’infrastructure d’Anthropic. Il faut donc vérifier vos règles de confidentialité, la nature des dépôts et les limites annoncées publiquement sur la conservation ou l’accès. Si vous avez des exigences fortes, you should relire les docs, contacter le support, et tester sur un repo non sensible before un déploiement large.
Comment obtenir ou activer Claude Code pour mon équipe ?
Il faut un plan Teams ou Enterprise, des droits admin sur Claude Code et sur l’organisation GitHub, puis installer l’app et choisir les dépôts. Ensuite, vous activez le comportement voulu, ouverture de PR, chaque push ou mode manuel. Le service est en research preview, donc l’accès n’est pas encore universel.
Le code de Claude est-il fiable pour la production ?
Il peut être utile, parfois très utile, mais not infaillible. Les chiffres internes publiés, comme le niveau proche de 99 % de pertinence ou la hausse de 54 % de PRs avec commentaires de fond, sont intéressants, mais ils ne dispensent pas de tests, d’audit et d’une validation humaine. En gros, utilisez-le pour gagner du temps et trouver des angles morts, pas pour déléguer entièrement votre jugement.
Analyse complète de Code Review : Anthropic Claude, avec fonctionnement multi-agent, installation sur GitHub, sécurité, coûts, limites, ROI et FAQ pour décider d’un déploiement en production.